今天第二篇(最近更新的都是Deep模型,传统的线性模型会后面找个时间更新的哈)。本篇介绍华为的DeepFM模型 (2017年),此模型在 Wide&Deep 的基础上进行改进,成功解决了一些问题,具体的话下面一起来看下吧。
原文:《Deepfm: a factorization-machine based neural network for ctr prediction》
1、问题由来
1.1、背景
CTR 预估 数据特点:
输入中包含类别型和连续型数据。类别型数据需要 one-hot, 连续型数据可以先离散化再 one-hot,也可以直接保留原值。
维度非常高。
数据非常稀疏。
特征按照 Field 分组。
CTR 预估重点在于学习组合特征。注意,组合特征包括二阶、三阶甚至更高阶的,阶数越高越复杂,越不容易学习。Google的研究者得出结论:高阶和低阶的组合特征都非常重要,同时学习到这两种组合特征的性能要比只考虑其中一种的性能要好。
那么关键问题转化成:如何高效的提取这些组合特征。一种办法就是引入领域知识人工进行特征工程。这样做的弊端是高阶组合特征非常难提取,会耗费极大的人力。而且,有些组合特征是隐藏在数据中的,即使是专家也不一定能提取出来,比如著名的“尿布与啤酒”问题。
在 DeepFM 提出之前,已有 LR,FM、FFM、FNN、PNN(以及三种变体:IPNN,OPNN,PNN*),Wide&Deep 模型,这些模型在 CTR 或者是推荐系统中被广泛使用。
1.2、现有模型的问题
线性模型:最开始 CTR 或者是推荐系统领域,一些线性模型取得了不错的效果(线性模型LR简单、快速并且模型具有可解释,有着很好的拟合能力),但是LR模型是线性模型,表达能力有限,泛化能力较弱,需要做好特征工程,尤其需要交叉特征,才能取得一个良好的效果,然而在工业场景中,特征的数量会很多,可能达到成千上万,甚至数十万,这时特征工程就很难做,还不一定能取得更好的效果。
FM模型:线性模型差强人意,直接导致了 FM 模型应运而生(在 Kaggle 上打比赛提出来的,取得了第一名的成绩)。FM 通过隐向量 latent vector 做内积来表示组合特征,从理论上解决了低阶和高阶组合特征提取的问题。但是实际应用中受限于计算复杂度,一般也就只考虑到 2 阶交叉特征。后面又进行了改进,提出了 FFM,增加了 Field 的概念。
遇上深度学习:随着 DNN 在图像、语音、NLP 等领域取得突破,人们渐渐意识到 DNN 在特征表示上的天然优势。相继提出了使用 CNN 或 RNN 来做 CTR 预估的模型。但是,CNN 模型的缺点是:偏向于学习相邻特征的组合特征。 RNN 模型的缺点是:比较适用于有序列 (时序) 关系的数据。
FNN 的提出,应该算是一次非常不错的尝试:先使用预先训练好的 FM,得到隐向量,然后作为 DNN 的输入来训练模型。缺点在于:受限于 FM 预训练的效果。
随后提出了 PNN,PNN 为了捕获高阶组合特征,在embedding layer和first hidden layer之间增加了一个product layer。根据 product layer 使用内积、外积、混合分别衍生出IPNN, OPNN, PNN*三种类型。
但无论是 FNN 还是 PNN,他们都有一个绕不过去的缺点:对于低阶的组合特征,学习到的比较少。 而前面我们说过,低阶特征对于 CTR 也是非常重要的。
Google(上一篇) 意识到了这个问题,为了同时学习低阶和高阶组合特征,提出了 Wide&Deep 模型。它混合了一个 线性模型(Wide part) 和 Deep 模型 (Deep part)。这两部分模型需要不同的输入,而 Wide part 部分的输入,依旧依赖人工特征工程。
但是,这些模型普遍都存在两个问题:
偏向于提取低阶或者高阶的组合特征,不能同时提取这两种类型的特征。
需要专业的领域知识来做特征工程。
于是DeepFM 应运而生,成功解决了这两个问题,并做了一些改进,其优点如下:
不需要预训练 FM 得到隐向量。
不需要人工特征工程。
能同时学习低阶和高阶的组合特征。
FM 模块和 Deep 模块共享 Feature Embedding 部分,可以更快的训练,以及更精确的训练学习。
下面就一起来走进模型的细节。
2、模型细节
DeepFM主要做法如下:
FM Component + Deep Component。FM 提取低阶组合特征,Deep 提取高阶组合特征。但是和 Wide&Deep 不同的是,DeepFM 是端到端的训练,不需要人工特征工程。
共享 feature embedding。FM 和 Deep 共享输入和feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep 中,input vector 非常大,里面包含了大量的人工设计的 pairwise 组合特征,增加了它的计算复杂度。
模型整体结构图如下所示: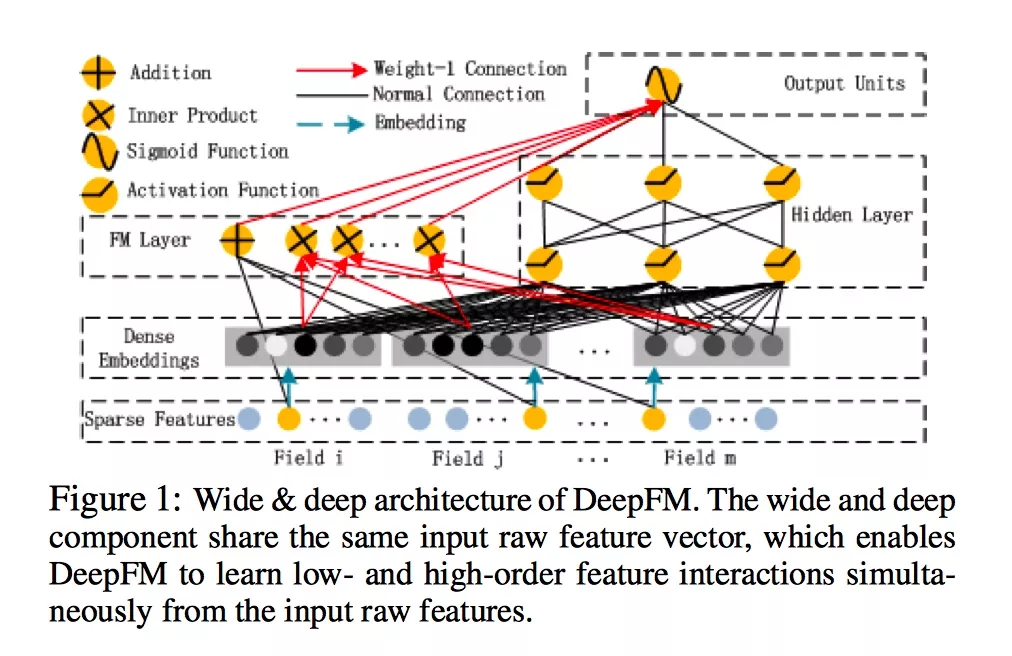
由上面网络结构图可以看到,DeepFM 包括 FM和 DNN两部分,所以模型最终的输出也由这两部分组成:
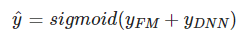
下面,把结构图进行拆分,分别来看这两部分。
2.1、The FM Component
FM 部分的输出由两部分组成:一个 Addition Unit,多个 内积单元。
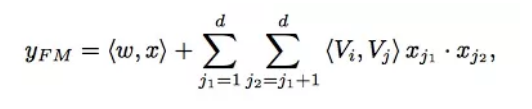
这里的 d 是输入 one-hot 之后的维度,我们一般称之为feature_size。对应的是 one-hot 之前的特征维度,我们称之为field_size。
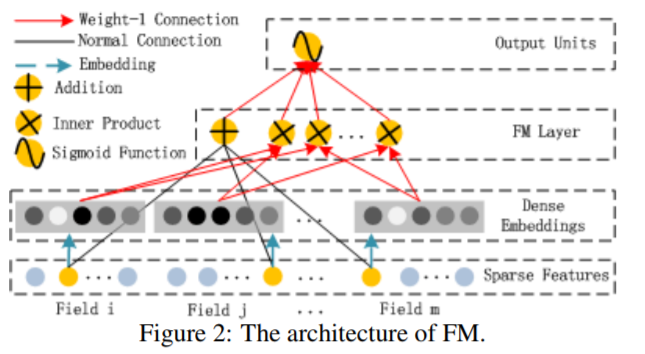
架构图如上图所示:Addition Unit 反映的是 1 阶的特征。内积单元 反映的是 2 阶的组合特征对于预测结果的影响。
这里需要注意三点:
这里的Wij,也就是
由于输入特征one-hot编码,所以embedding vector也就是输入层到Dense Embeddings层的权重。
Dense Embeddings层的神经元个数是由embedding vector和field_size共同确定,直观来说就是:神经元的个数为embedding vector * field_size。
FM Component 总结:
FM 模块实现了对于 1 阶和 2 阶组合特征的建模。
无须预训练。
没有人工特征工程。
embedding 矩阵的大小是:特征数量 * 嵌入维度。然后用一个 index 表示选择了哪个特征。
需要训练的有两部分:
input_vector 和 Addition Unit 相连的全连接层,也就是 1 阶的 Embedding 矩阵。
Sparse Feature 到 Dense Embedding 的 Embedding 矩阵,中间也是全连接的,要训练的是中间的权重矩阵,这个权重矩阵也就是隐向量 Vi。
2.2、The Deep Component
Deep Component 架构图:
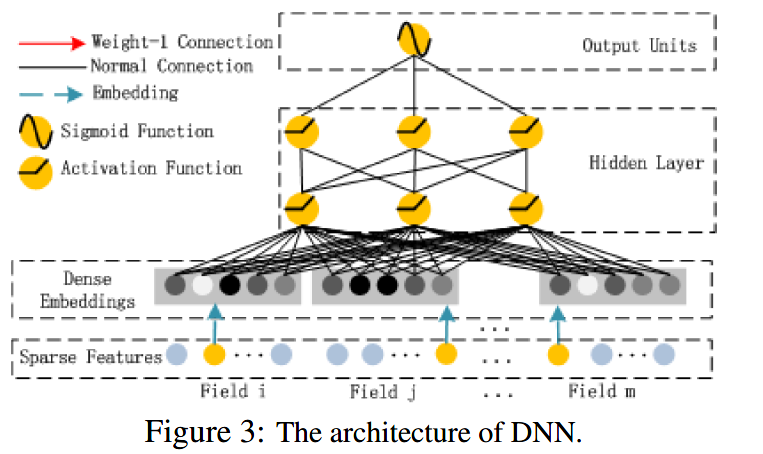
这里DNN的作用是构造高阶组合特征,网络里面黑色的线是全连接层,参数需要神经网络去学习。且有一个特点:DNN的输入也是embedding vector。所谓的权值共享指的就是这里。
关于DNN网络中的输入a处理方式采用前向传播,如下所示:
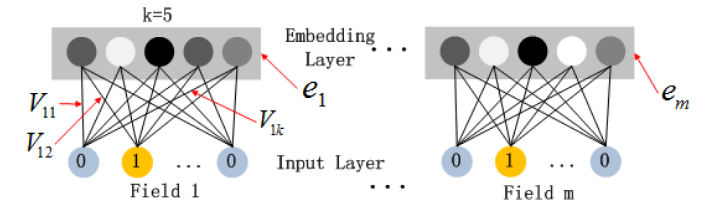
这里假设α(0)=(e1,e2,…em)表示 embedding层的输出,那么α(0)作为下一层 DNN隐藏层的输入,其前馈过程如下:
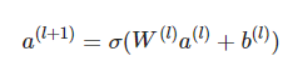
优点:
模型可以从最原始的特征中,同时学习低阶和高阶组合特征
不再需要人工特征工程。Wide&Deep 中低阶组合特征就是通过特征工程得到的。
3、总结(具体的对比实验和实现细节等请参阅原论文)
DeepFM优点:
没有用 FM 去预训练隐向量 Vi,并用 Vi去初始化神经网络。(相比之下 FNN 就需要预训练 FM 来初始化 DNN)。
FM 模块不是独立的,是跟整个模型一起训练学习得到的。(相比之下 Wide&Deep 中的 Wide 和 Deep 部分是没有共享的)
不需要特征工程。(相比之下 Wide&Deep 中的 Wide 部分需要特征工程)
训练效率高。(相比 PNN 没有那么多参数)
其中最核心的:
没有预训练(no pre-training)
共享 Feature Embedding,没有特征工程(no feature engineering)
同时学习低阶和高阶组合特征(capture both low-high-order interaction features)
实现DeepFM的一个Demo,感兴趣的童鞋可以关注我的github。