本人才疏学浅,不足之处欢迎大家指出和交流。
今天要分享的是2017年斯坦福与Google联合提出的DCN模型,和明天要分享的XDeepFM是配套的,同时这篇论文是Google 对 Wide & Deep工作的一个后续研究。本人写文章的顺序尽量严格按照时间顺序来的~话不多说,来看看今天分享的深度模型(串行结构)有哪些创新之处吧。
原文:《Deep & Cross Network for Ad Click Predictions》
1、背景及相关工作
(每篇文章都重复下这些背景哈,希望大家别看烦,尽量换种方式):传统的CTR预估模型需要大量的人工特征工程,耗时耗力;引入DNN之后,依靠神经网络强大的学习能力,可以一定程度上实现自动学习特征组合。但是DNN的缺点在于隐式的学习特征组合带来的不可解释性,以及低效率的学习(并不是所有的特征组合都是有用的)。这时交叉网络应运而生,同时联合DNN,发挥两者的共同优势。传统的CTR预估模型需要大量的人工特征工程,耗时耗力;引入DNN之后,依靠神经网络强大的学习能力,可以一定程度上实现自动学习特征组合。但是DNN的缺点在于隐式的学习特征组合带来的不可解释性,以及低效率的学习(并不是所有的特征组合都是有用的)。这时交叉网络应运而生,同时联合DNN,发挥两者的共同优势。
相关工作:由于数据集规模和维数的急剧增加,之前已经提出了许多方法:
最开始FM使用隐向量的内积来建模组合特征;
FFM在此基础上引入field的概念,针对不同的field使用不同的隐向量。
但是,这两者都是针对低阶(二阶,高阶会产生非常大的计算成本)的特征组合进行建模的;随着DNN在计算机视觉、自然语言处理、语音识别等领域取得重要进展,DNN几乎无限的表达能力被广泛的研究。同样也尝试被用来解决web产品中输入数据高维高稀疏的问题。DNN可以对高维组合特征进行建模,但是DNN的不可解释性让DNN是否是目前最高效的针对此类问题的建模方式成为了一个问题; 另一方面,在Kaggle上的很多比赛中,大部分的获胜方案都是使用的人工特征工程,构造低阶的组合特征,这些特征意义明确且高效。而DNN学习到的特征都是隐式的、高度非线性的高阶组合特征,含义非常难以解释。这揭示了一个模型能够比通用的DNN设计更能够有效地学习的有界度特征的相互作用,那是否能设计一种DNN的特定网络结构来改善DNN,使得其学习起来更加高效呢?
Wide&Deep是其中一个探索的例子,它以交叉特征作为一个线性模型的输入,与一个DNN模型一起训练,然而,W&D网络的成功取决于正确的交叉特征的选择(仍依赖人工特征工程),这是一个至今还没有明确有效的方法解决的指数问题。
于是提出DCN进行进一步探索,将Wide部分替换为由特殊网络结构实现的Cross,自动构造有限高阶的交叉特征,并学习对应权重,告别了繁琐的人工叉乘。下面一起来看下细节:
2、DEEP & CROSS NETWORK
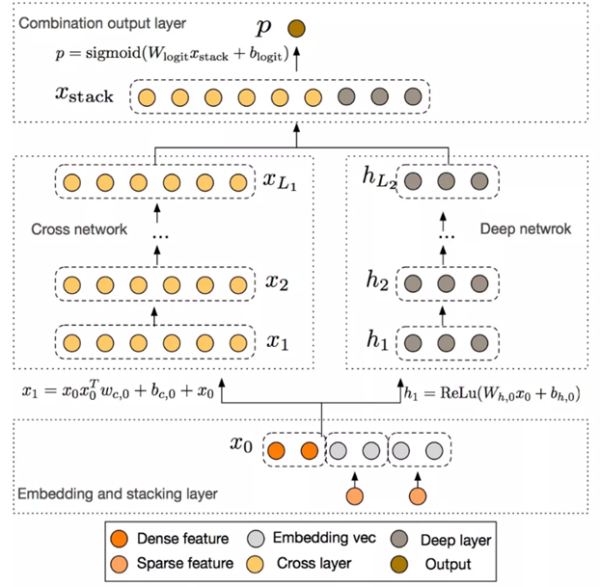
DCN整体模型的架构图如上:底层是Embedding and stacking layer,然后是并行的Cross Network和Deep Network,最后是Combination Layer把Cross NetworkDeep Network的结果stack得到Output。
2.1 Embedding and stacking layer
DCN底层的两个功能是Embed和Stack;
Embed:
在web-scale的推荐系统比如CTR预估中,输入的大部分特征都是类别型特征,通常的处理办
法就是编码为one-hot向量,对于实际应用中维度会非常高且稀疏,因此使用嵌入层来将这些离散特征转换成实数值的稠密向量。
Stack:
处理完了类别型特征,还有连续型特征需要处理。所以我们把连续型特征规范化之后,和嵌入向量stacking(堆叠)到一起形成一个向量,就得到了原始的输入: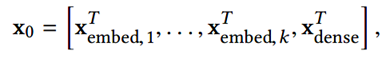
2.2 Cross network
Cross Network是这个模型的核心,它被设计来高效地应用显式的交叉特征,关键在于如何高效地进行feature crossing。对于每层的计算,使用下述公式: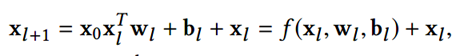
其中xl和xl+1 分别是第l层和第l+1层cross layer的输出(的列向量),wl和bl是这两层之间的连接参数。注意上式中所有的变量均是列向量,W也是列向量,并不是矩阵。
理解:
这其实应用了残差网络的思想,xl+1 = f(xl, wl, bl) + xl:每一层的输出,都是上一层的输出加上feature crossing f。而f就是在拟合该层输出和上一层输出的残差(xl+1−xl)。残差网络有很多优点,其中一点是处理梯度退化/消失的问题,使神经网络可以“更深”.一层交叉层的可视化如下图所示: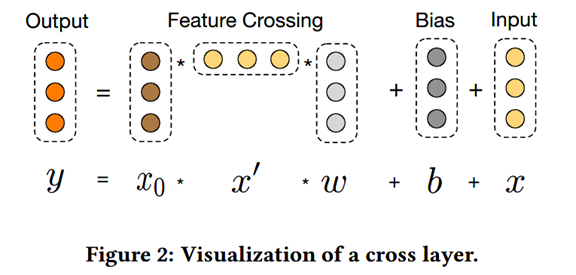
High-degree Interaction Across Features:
Cross Network特殊的网络结构使得cross feature的阶数随着layer depth的增加而增加。相对于输入x0来说,一个l层的cross network的cross feature的阶数为l+1。
复杂度分析:
假设一共有Lc层cross layer,起始输入x0的维度为d。那么整个cross network的参数个数为: d × Lc × 2 ;
因为每一层的W和b都是d维的。从上式可以发现,复杂度是输入维度d的线性函数,所以相比于deep network,cross network引入的复杂度微不足道。这样就保证了DCN的复杂度和DNN是一个级别的。论文中分析Cross Network的这种效率是因为x0 * xT的秩为1,使得我们不用计算并存储整个的矩阵就可以得到所有的cross terms。
但是,正是因为cross network的参数比较少导致它的表达能力受限,为了能够学习高阶非线性的组合特征,DCN并行的引入了Deep Network。
2.3 Deep network
深度网络就是一个全连接的前馈神经网络,层数可以自己设定;
分析计算一下参数的数量来估计下复杂度。假设输入x0维度为d,一共有Lc层神经网络,每一层的神经元个数都是m个。那么总的参数或者复杂度为: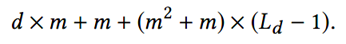
2.4 Combination layer
Combination Layer把Cross Network和Deep Network的输出拼接起来,然后经过一个加权求和后得到logits,然后输入到标准的逻辑回归函数得到最终的预测概率。形式化如下: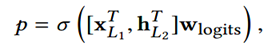
p是最终的预测概率;XL1是d维的,表示Cross Network的最终输出;hL2是m维的,表示Deep Network的最终输出;Wlogits是Combination Layer的权重;最后经过sigmoid函数,得到最终预测概率。
损失函数使用带正则项的log loss,形式化如下: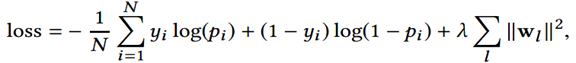
此外,Cross Network和Deep Network,DCN是一起训练Cross Network和Deep Network的,这样网络可以知道另外一个网络的存在。
3、CROSS NETWORK ANALYSIS
本节是为了解释DCN的高效性,从三个角度:
1、polynomial approximation;2、generalization to FMs;3、efficientprojection。
(具体的分析请大家参阅原论文:这部分是非常重要的一部分,是论文中解释DCN为何高效的理论部分,从数学上证明了为何递归叉乘部分包含了所有低阶特征组合)
4、总结(具体的对比实验和实现细节等请参阅原论文)
DCN模型的特点:
1. 在cross network中,在每一层都应用feature crossing。高效的学习了bounded degree组合特征。不需要人工特征工程。
2. 网络结构简单且高效。多项式复杂度由layer depth决定。
3. 相比于DNN,DCN的logloss更低,而且参数的数量将近少了一个数量级。
4. 但是经过对cross network的分析如下,最终得到的输出就相当于X0 不断乘以一个数(标量),而且它们的特征交互是发生在元素级(bit-wise)。这种处理方式可能是存在问题的。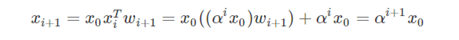
(当然,指出这些问题的就是我们下一篇论文XDeepFM啦,我们下篇再见)
实现DCN的一个Demo,感兴趣的童鞋可以看下我的github。