本人才疏学浅,不足之处欢迎大家指出和交流。
本系列接下来几天要分享的文章是关于线性模型的,在15年后深度模型在ctr预估领域百花齐放之时,仍觉得传统的LR模型有着基石的作用,于是有了今天的分享。话不多说,今天会介绍的是经典的LR模型及Facebook在2014年提出的GBDT+LR(重点)。当时深度学习几乎还没有应用到到计算广告/推荐系统领域,Facebook提出利用GBDT的叶节点编号作为非线性特征的表示,或者说是组合特征的一种方式,可以自动实现特征工程,下面我们一起来看看吧。
两篇原文:
1、背景
这里是微软研究院在当时提出LR模型时的商业背景:搜索引擎主要靠商业广告收入,在广告位上面打广告,用户点击,之后广告商付费。在通用搜索引擎,通常广告位置是在搜索结果之前,或者在搜索结果右边,由此为查询选择正确的广告及其展示顺序会极大地影响用户看到并点击每个广告的概率。此排名对搜索引擎从广告中获得的收入产生了很大影响。此外,向用户展示他们喜欢点击的广告也会提高用户满意度。出于这些原因,能够准确估计系统中广告的点击率非常重要(朴素的想法即是放用户可能点击的广告,并且放每次点击广告商付费多的广告)。
于是就归结到点击率预估的模型选择和特征工程问题。
2、LR Model
2.1 LR的数学基础
为何在2012年之前LR模型占据了计算广告领域的极大部分市场呢,我们可以从数学角度稍作分析:
逻辑回归(logistics regression)作为广义线性模型的一种,它的假设是因变量y服从伯努利分布。那么在点击率预估这个问题上,“点击”这个事件是否发生就是模型的因变量y。而用户是否点击广告这个问题是一个经典的掷偏心硬币(二分类)问题,因此CTR模型的因变量显然应该服从伯努利分布。所以采用LR作为CTR模型是符合“点击”这一事件的物理意义的。
在了解这一基础假设的情况下,再来看LR的数学形式就极具解释性了:
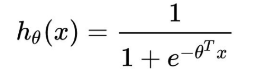
其中x是输入向量,θ 是我们要学习的参数向量。结合CTR模型的问题来说,x就是输入的特征向量,h(x)就是我们最终希望得到的点击率。
2.2、朴素的直觉和可解释性
直观来讲,LR模型目标函数的形式就是各特征的加权和,最后再加以sigmoid函数。忽略其数学基础,仅靠我们的直觉认知也可以一定程度上得出使用LR作为CTR模型的合理性:
使用各特征的加权和是为了综合不同特征对CTR的影响,而由于不同特征的重要程度不一样,所以为不同特征指定不同的权重来代表不同特征的重要程度。最后要加上sigmoid函数,是希望其值能够映射到0-1之间,使其符合CTR的概率意义。
对LR的这一直观(或是主观)认识的另一好处就是模型具有极强的可解释性,算法工程师们可以轻易的解释哪些特征比较重要,在CTR模型的预测有偏差的时候,也可以轻易找到哪些因素影响了最后的结果。
2.3、工程化的需要
在工业界每天动辄TB级别的数据面前,模型的训练开销就异常重要了。在GPU尚未流行开来的2012年之前,LR模型也凭借其易于并行化、模型简单、训练开销小等特点占据着工程领域的主流。囿于工程团队的限制,即使其他复杂模型的效果有所提升,在没有明显beat LR之前,公司也不会贸然加大计算资源的投入升级CTR模型,这是LR持续流行的另一重要原因。
3、GBDT+LR Model
这篇文章(原文2)主要介绍了CTR预估模型LR(Logistic Regression)+GBDT。当时深度学习还没有应用到计算广告领域,而在此之前为探索特征交叉而提出的FM(见本系列第一篇)和FFM(本系列忘写了…)虽然能够较好地解决数据稀疏性的问题,但他们仍停留在二阶交叉的情况。如果要继续提高特征交叉的维度,不可避免的会发生组合爆炸和计算复杂度过高等问题。在此基础上,2014年Facebook提出了基于GBDT+LR组合模型的解决方案。简而言之,Facebook提出了一种利用GBDT(Gradient Boosting Decision Tree)自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量当作LR模型输入,预估CTR的模型结构。随后Kaggle竞赛也有实践此思路,GBDT与LR融合开始引起了业界关注。
LR+GBDT相比于单纯的LR或者GBDT带来了较大的性能提升,论文中给出数据为3%,这在CTR预估领域确实非常不错。除此之外,Facebook还在在线学习、Data freshness、学习速率、树模型参数、特征重要度等方面进行了探索(本文不做讨论,有兴趣可参阅原文)。Online Learning是本文的一个重点,接下来我们会提到。
3.1、GBDT
GBDT 由多棵 CART 树组成,本质是多颗回归树组成的森林。每一个节点按贪心分裂,最终生成的树包含多层,这就相当于一个特征组合的过程。根据规则,样本一定会落在一个叶子节点上,将这个叶子节点记为1,其他节点设为0,得到一个向量。论文中如下图所示:有两棵树,第一棵树有三个叶子节点,第二棵树有两个叶子节点。如果一个样本落在第一棵树的第二个叶子,将它编码成 [0, 1, 0]。在第二棵树落到第一个叶子,编码成 [1, 0]。所以,输入到 LR 模型中的向量就是 [0, 1, 0, 1, 0]。
需要注意的一点是:利用 GBDT 模型进行自动特征组合和筛选是一个独立(独立于LR训练)的过程,于是乎这种方法的优点在于两个模型在训练过程中是独立进行的,不需要进行联合训练,自然也就不存在如何将LR的梯度回传到GBDT这类复杂的问题。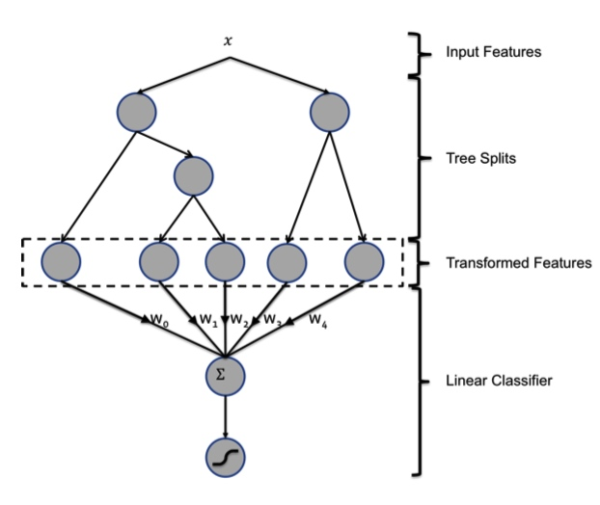
然而,还有两个重要问题是为什么建树采用GBDT以及为什么要使用集成的决策树模型,而不是单棵的决策树模型呢?
对于第二个问题,我们可以认为一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些,可以更好的发现有效的特征和特征组合。
对于第一个问题,牵涉到GBDT原理问题,这里不做过多讨论,请参考两篇网上写的较好的文章:
3.2、GBDT+LR总结
由于决策树的结构特点,事实上,决策树的深度就决定了特征交叉的维度。如果决策树的深度为4,通过三次节点分裂,最终的叶节点实际上是进行了3阶特征组合后的结果,如此强的特征组合能力显然是FM系的模型不具备的。但由于GBDT容易产生过拟合,以及GBDT这种特征转换方式实际上丢失了大量特征的数值信息,因此我们不能简单说GBDT由于特征交叉的能力更强,效果就比FM或FFM好(事实上FFM是2015年提出的)。在模型的选择和调试上,永远都是多种因素综合作用的结果。
GBDT+LR比FM重要的意义在于,它大大推进了特征工程模型化这一重要趋势,某种意义上来说,之后深度学习的各类网络结构,以及embedding技术的应用,都是这一趋势的延续。
4、总结(具体的对比实验和实现细节等请参阅原论文)
本次简要介绍了传统的LR模型,其优点和缺点都非常突出,但不可否认的是其基石般的作用和地位。同时我们也介绍了GBDT+LR的改进方案以解决特征组合的问题,但GBDT也存在很容易过拟合的问题,接下来这段话摘自于知乎:

这里是引用阿里的盖坤大神的回答,他认为GBDT只是对历史的一个记忆罢了,没有推广性,或者说泛化能力。 番外:盖坤大神的团队在2017年提出了两个重要的用于CTR预估的模型,MLR(实际开始应用于2012年)和DIN,后面的线性模型和深度模型也会更新这两篇,下篇再见吧~
实现GBDT+LR的一个Demo,感兴趣的童鞋可以看下我的github。
巨人的肩膀:https://blog.csdn.net/shenziheng1/article/details/89737467