本人才疏学浅,不足之处欢迎大家指出和交流。
今天要分享的是阿里针对电子商务领域的CTR预估的Deep Interest Network理论,由盖坤大神团队提出于2017年。该模型要点为:结合Attention机制,充分利用/挖掘用户历史行为数据中的信息,下面一起来看下。
原文:《Deep Interest Network for Click-Through Rate Prediction》
地址: https://www.ijcai.org/proceedings/2017/0435.pdf
1、 背景
自Youtube 提出来基于 embedding 和 MLP 的基础模型后,近年来深度学习在CTR预估领域已经有了广泛的应用,常见的算法有如如Wide&Deep,DeepFM等。在这些方法中,大规模稀疏输入首先将特征映射到某固定维度的嵌入向量,然后通过多个MLP,以了解特征之间的非线性关系。这样,无论候选广告是什么,用户特征都被压缩为固定长度的表示向量。
这种方法的优点在于:通过神经网络可以拟合高阶的非线性关系,同时减少了人工特征的工作量。
但是,使用固定长度的矢量将成为瓶颈,这给嵌入和MLP方法从丰富的历史行为中有效捕捉用户的不同兴趣带来了困难。
于是文中提出了DIN网络来解决这个问题,该网络设计了一个局部激活单元来自适应地从和某个广告相关的历史行为中学习用户兴趣。这个表示向量会因广告而异,极大地提高了模型的表达能力。
提前来看下DIN具体的解决方案总结:
- 使用_用户兴趣分布_来表示用户多种多样的兴趣爱好
- 使用_Attention机制_来实现Local Activation
- 针对模型训练,提出了_Dice激活函数,自适应正则_,显著提升了模型性能与收敛速度
1.1 数据特性
在丰富的线上电商数据中,研究者们通过观察发现了用户行为数据中有两个很重要的特性:
Diversity:
用户在访问电商网站时会对多种商品都感兴趣。也就是用户的兴趣非常的广泛。
Local Activation:
用户是否会点击推荐给他的商品,仅仅取决于历史行为数据中的一小部分,而不是全部。
举个栗子:
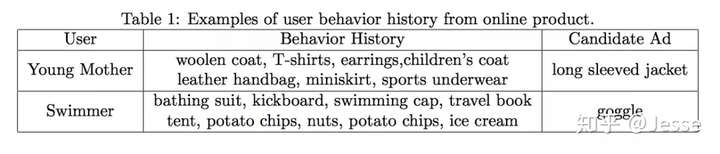
Diversity:一个年轻的母亲,从她的历史行为中,我们可以看到她的兴趣非常广泛:羊毛衫、手提袋、耳环、童装、运动装等等。
Local Activation:一个爱游泳的人,他之前购买过travel book、ice cream、potato chips、swimming cap。当前给他推荐的商品(或者说是广告)是goggle。那么他是否会点击这次广告,跟他之前是否购买过薯片、书籍、冰激凌没有任何相关性,而是与他之前购买过游泳帽有关。也就是说在这一次CTR预估中,部分历史数据(swimming cap)起了决定作用,而其他的基本都没起作用。
针对上面提到的用户行为中存在的两种特性,阿里将其运用于自身的推荐系统中,推出了深度兴趣网络DIN,接下来,我们就一起来看一下推荐系统和模型的一些实现细节。
2、系统设计
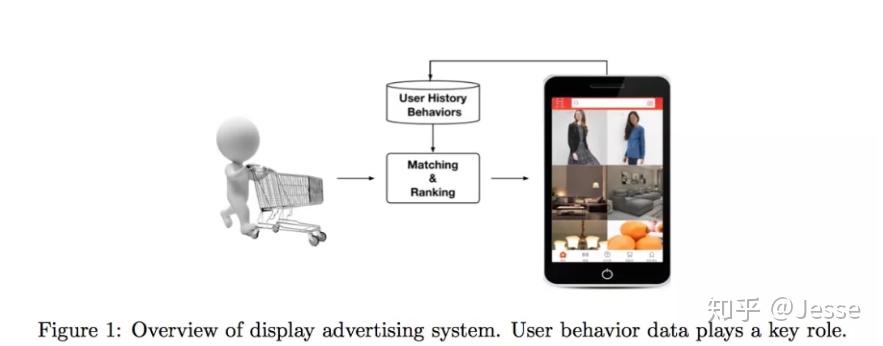
阿里的推荐系统工作流程就如上图所示,可以简单描述为:
- 检查用户历史行为数据。
- 使用matching module产生候选ads。
- 通过ranking module得到候选ads的点击概率,并根据概率排序得到推荐列表。
- 记录下用户在当前展示广告下的反应(点击与否)。
这是一个闭环的系统,对于用户行为数据(User Behavior Data),系统自己生产并消费。
2.1、特征设计
论文中将所涉及到的特征分为四个部分:用户特征、用户行为特征、广告特征、上下文特征,并没有进行特征组合/交叉特征。而是通过DNN去学习特征间的交互信息。具体如下:
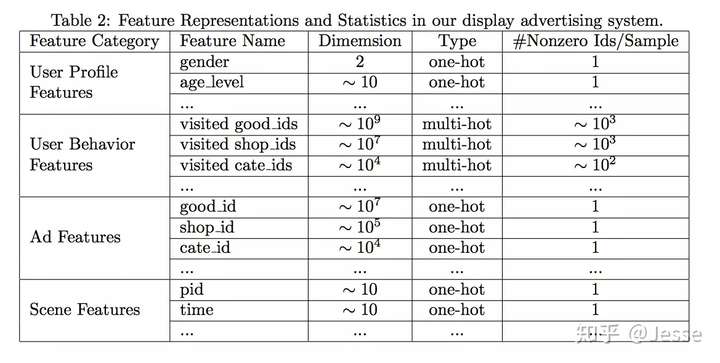
其中,只有用户行为特征是multi-hot的,即多值离散特征,原因就是一个用户会购买多个good_id,也会访问多个shop_id。针对这种特征,由于每个涉及到的非0值个数是不一样的,常见的做法就是将id转换成embedding之后,加一层pooling层,比如average-pooling,sum-pooling,max-pooling。DIN中使用的是weighted-sum,其实就是加权的sum-pooling,权重经过一个activation unit计算得到。即Embedding -> Pooling + Attention,后面还会具体介绍。
2.2、评价指标
模型使用的评价指标是GAUC,我们先来看一下GAUC的计算公式:
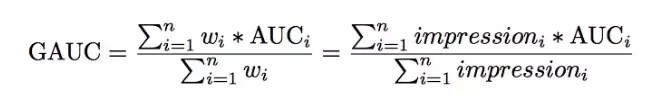
AUC表示正样本得分比负样本得分高的概率。在CTR实际应用场景中,CTR预测常被用于对每个用户候选广告的排序。但是不同用户之间存在差异:有些用户本身就是点击率较高。以往的评价指标对样本不区分用户地进行AUC的计算。论文采用的GAUC实现了用户级别的AUC计算,在单个用户AUC的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响,更准确的描述了模型的表现效果,并且实践证明了GAUC相比于AUC更加稳定、可靠。
3、DIN
3.1、Base Model
在介绍DIN之前,我们先来看一下一个base,结构如下:

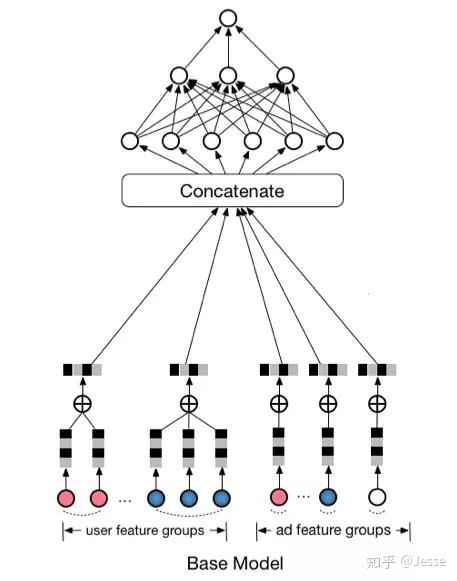
可以看到,Base Model首先吧one-hot或multi-hot特征转换为特定长度的embedding,作为模型的输入,然后经过一个DNN的part,得到最终的预估值。特别地,针对multi-hot的特征,做了一次element-wise+的操作,这里其实就是sum-pooling,这样,不管特征中有多少个非0值,经过转换之后的长度都是一样的。
这里对multi-hot多值离散特征进行Pooling操作,就是对Diversity的建模。Base Model中还没有引入Attention机制。
3.2、Deep Interest Network
仔细研究我们可以发现,Base Model有一个很大的问题,Pooling操作损失了很多信息,它对用户的历史行为是同等对待的,没有做任何处理,这显然是不合理的。一个很显然的例子,离现在越近的行为,越能反映你当前的兴趣。因此,对用户历史行为基于Attention机制进行一个加权,阿里提出了深度兴趣网络(Deep Interest Network),先来看一下模型结构:
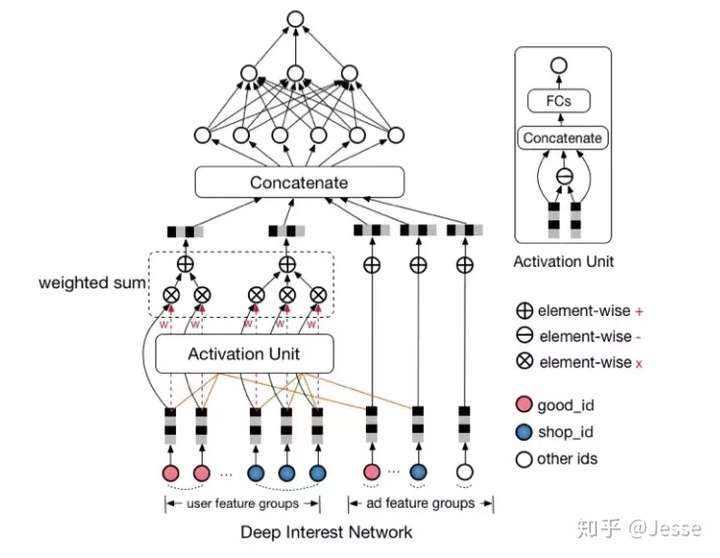
首先给出结论,在这个模型中:
- Activation Unit实现Attention机制,对Local Activation建模
- Pooling(weighted sum)对Diversity建模
第二点比较好理解,接下来重点来理解下第一点。
Attention:基于用户历史行为,充分挖掘用户兴趣和候选广告之间的关系。用户是否点击某个广告往往是基于他之前的部分兴趣,这是应用Attention机制的基础。Attention机制简单的理解就是对于不同的特征有不同的权重,这样某些特征就会主导这一次的预测,就好像模型对某些特征pay attention。但是,DIN中并不能直接用attention机制。因为对于不同的候选广告,用户兴趣表示(embedding vector)应该是不同的。也就是说用户针对不同的广告表现出不同的兴趣表示,即使是历史兴趣行为相同,但是各个行为的权重不同。这就是DIN针对Local Activation建模的含义。
attention在这里的实际意义是:每个Ad,都有一堆历史行为对其产生attention的影响分,这些attention分值与历史行为共同对这个Ad下的用户表示做加权。(可以将行为结构信息保留下来,并且提供了注意焦点)如下:
用户在某个广告下的Embedding表示Vu(Va):
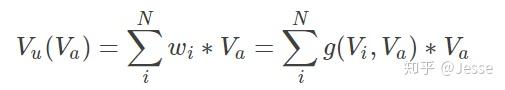
其中,Vu是所有behavior ids的加权和,表示的是用户兴趣;Va是候选广告的嵌入向量;wᵢ是候选广告影响着每个behavior id的权重,也就是Local Activation。wᵢ通过Activation Unit计算得出,这一块用函数去拟合,表示为g(Vi,Va)。
3.3、 Dice激活函数
从Relu到PRelu:
PReLU其实是ReLU的改良版,ReLU可以看作是x*Max(x,0),相当于输出x经过了一个在0点的阶跃整流器。由于ReLU在x小于0的时候,梯度为0,可能导致网络停止更新,PReLU对整流器的左半部分形式进行了修改,使得x小于0时输出不为0。
研究表明,PReLU能提高准确率但是也稍微增加了过拟合的风险。PReLU形式如下:
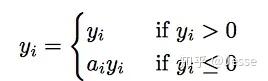
无论是ReLU还是PReLU突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点而是应该依赖于数据的。于是提出了一种data dependent的方法:Dice激活函数。形式如下:
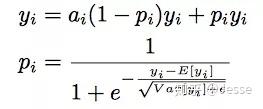
可以看出,pi是一个概率值,这个概率值决定着输出是取yi或者是alpha_i * yi,pi也起到了一个整流器的作用。
pi的计算分为两步:
- 首先,对x进行均值归一化处理,这使得整流点是在数据的均值处,实现了data dependent的想法;
- 其次,经过一个sigmoid函数的计算,得到了一个0到1的概率值。巧合的是最近google提出的Swish函数形式为
x*sigmoid(x)在多个实验上证明了比ReLU函数x*Max(x,0)表现更优。
另外,期望和方差使用每次训练的mini batch data直接计算,并类似于Momentum使用了_指数加权平均_:
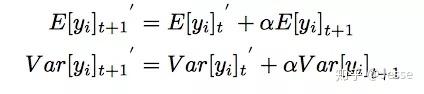
alpha是一个超参数,推荐值为0.99。
3.4、 自适应正则 Adaptive Regularization
在深度ctr模型中,输入非常稀疏且维度高,模型稍微复杂导致参数非常多,通常的做法是加入L1、L2、Dropout等防止过拟合,论文中尝试后效果都不是很好。同时研究者们也发现用户数据符合长尾定律,也就是说很多的feature id只出现了几次,而一小部分feature id出现很多次。这在训练过程中增加了很多噪声,并且加重了过拟合。
对于这个问题一个简单的处理办法就是:人工的去掉出现次数比较少的feature id。缺点是:损失的信息不好评估;阈值的设定非常的粗糙。
DIN给出的解决方案是:
- 针对feature id出现的频率,来自适应的调整他们正则化的强度;
- 对于出现频率高的,给与较小的正则化强度;
- 对于出现频率低的,给予较大的正则化强度。
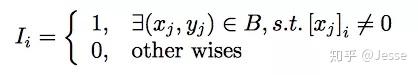
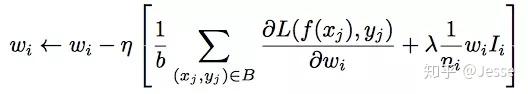
其中B是mini batch样本,大小为b;ni是出现频率;Ii表示我们考虑特征非零的样本。
这样做的原因是,作者实践发现出现频率高的物品无论是在模型评估还是线上收入中都有较大影响。
4、结果展示
下图展示了用户兴趣分布:颜色越暖表示用户兴趣越高,可以看到用户的兴趣分布有多个峰。
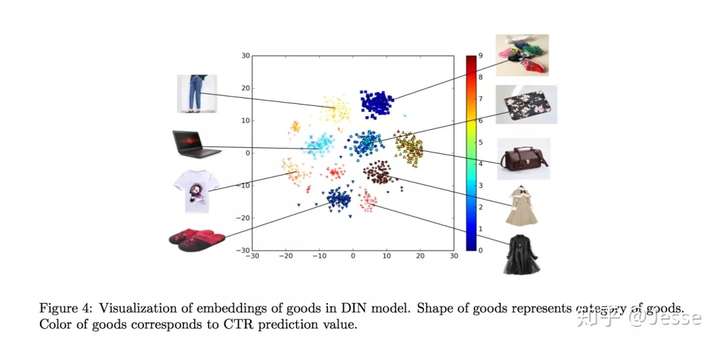
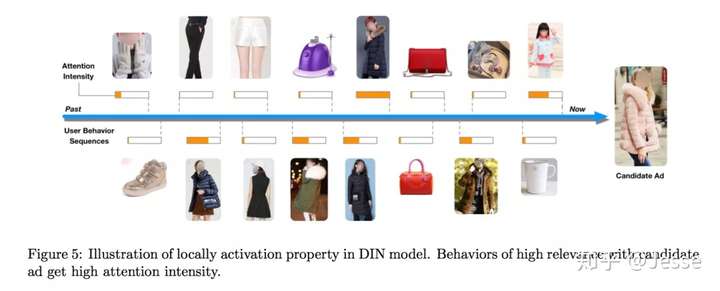
利用候选的广告,反向激活历史兴趣。不同的历史兴趣爱好对于当前候选广告的权重不同,做到了local activation,如下图:
5、实验
Amazon Dataset
作者选取了Electronics 子集 ,包含192,403 users, 63,001 goods, 801 categories and 1,689,188 samples。该数据集中的用户行为比较多,每个用户的商品有超过5个用户评论。特征包括goods_id, cate_id, user reviewed goods_id_list and cate_id_list。假设一个用户的行为是 ,那么认为就是使用前面k个看过的物品预测第k+1个物品。Training dataset is generated with k = 1, 2, . . . , n 2 for each user,测试集是使用前面n-1个看过的物品预测最后一个物品。
对所有模型使用 SGD as the optimizer with exponential decay, 学习率从1开始衰减到0.1。min-batch大小为32。
MovieLens Dataset
contains 138,493 users, 27,278 movies, 21 categories and 20,000,263 samples。
为了让其适合ctr任务,作者将其转换为二分类数据。之前电影评分为0-5,作者将4、5标注为正样本,其余为负样本。根据userId来划分训练集和测试集。among all 138,493 users, of which 100,000 are randomly selected into training set (about 14,470,000 samples) and the rest 38,493 into the test set (about 5,530,000 samples).
任务变成:根据用户的历史行为,判断用户是否会对某个电影打分超过3分。Features include movie_id, movie_cate_id and user rated movie_id_list, movie_cate_id_list。optimizer, learning rate and mini-batch size 和上一个数据集相同。
Alibaba Dataset
取自阿里展示广告系统 线上流量,两周做训练集,接下来的一天为测试集。训练集和测试集大小分别为20亿和1.4亿。
For all the deep models, the dimensionality of embedding vector is 12 for the whole 16 groups of features. Layers of MLP issetby192⇥200⇥80⇥2.
由于数据量大,mini-batch size 为5000,Adam 为优化器。同时使用了指数衰减 in which learning rate starts at 0.001 and decay rate is set to 0.9.
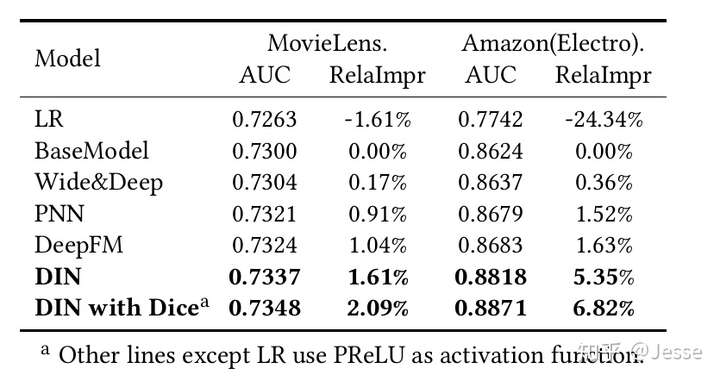
所有实验重复5次,平均指标作为最终指标。
1.DNN 均超过LR。
2.PNN和DeepFM 超过W&D。
3.DIN效果最好,尤其在amazon上,作者归因于局部激活单元的作用。
4.Dice 是有效的。
其他相关实验其参阅原论文,本次就聊到这里啦。
实现DIN的一个Demo,感兴趣的童鞋可以看下我的[github]。