由于秋招原因许久未更,现开始逐步看今天最近的论文。 今天分享的是微博&腾讯关于CTR预估的一篇文章:GateNet:Gating-Enhanced Deep Network for Click-Through Rate Prediction.
要点:在点击率预测中,当前的深度学习模型中基本都包括embedding layer和MLP hidden layers。另一方面,门控机制(gating mechanism)也广泛应用于许多研究领域,如计算机视觉和自然语言处理。目前已有一些研究证明了门控机制提高了非凸深度神经网络的可训练性,于是本文将门控机制与深度CTR模型相结合,并通过实验证明融合模型的性能取得了较大的提升。下面一起来看下细节。
原文:《GateNet:Gating-Enhanced Deep Network for Click-Through Rate Prediction》
1、 引入
首先是常见的CTR和深度CTR模型,如FM,DeepFM,Wide&Deep,DCN,xDeepFM等,之前都已经介绍过,还不了解的同学可以查看之前的文章,这里就不详细介绍了。接下来简单介绍下门机制。
门机制(gating mechanism)
目前,门机制广泛用于CV和NLP,CV如Highway Network,它们利用转换门和进位门来分别表示通过转换输入和进位输出产生了多少输出。在NLP中,如LSTM,GRU,语言建模,序列对序列学习,他们利用门来防止梯度消失和解决长期依赖问题。
此外,在推荐系统中使用门来自动调整建模共享信息和建模任务特定信息之间的参数。应用门机制的另一个推荐系统是hierarchical gating network(HGN),它应用特征级和实例级的门模块来自适应地控制哪些item潜在特征和哪些相关item可以被传递到下游层。具体的细节大家可以参阅上面提到这些的原论文。简单来理解,门控机制即相当于一个调节阀,可以控制流入的信息流量的流入程度。
由于目前推荐系统中常用的深度学习模型基本都包括embedding layer和MLP hidden layers,本文就在此基础上将门机制和这两种layer相结合,产生Feature Embedding Gate和Hidden Gate,接下来对二者分别介绍模型细节。
2、 模型
2.1 Feature Embedding Gate
Feature Embedding Gate主要是在嵌入层环节增加了门控机制,用于从特征中选择更为重要的特征(信息选择)。如果模型中带有Feature Embedding Gate,其网络结构如下图所示:
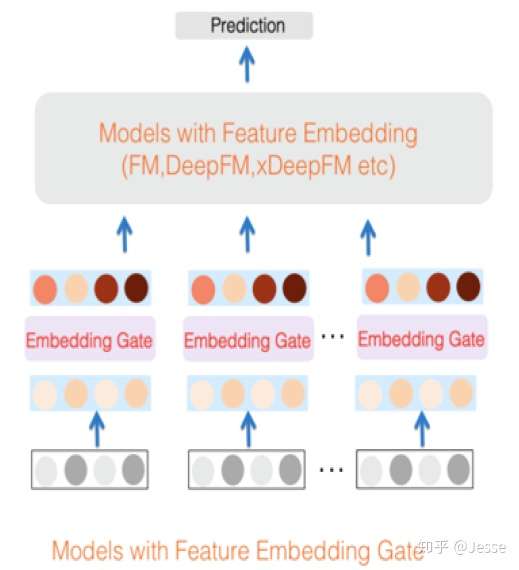
假设输入的离散特征经过Embedding layer得到E=[e1,e2,e3,…,ei,…ef],其中f代表特征域的个数,ei 代表第i个域的embedding向量,长度为K。
接下来,E会通过Feature Embedding Gate进行转换。首先,对每一个embedding向量,通过下面的公式来计算门值 gi ,代表该嵌入向量的特征重要程度:
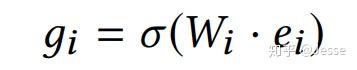
然后,将嵌入向量ei和门值 gi 计算哈达玛积,得到gei ,并得到最终的输出GE,如下公式:
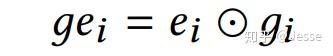
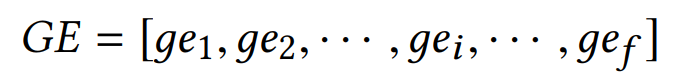
上面只是对Feature Embedding Gate的一个简要的介绍,其具体的做法包括多种(后面会有实验对比效果),比如输出的 gi 是一个跟 ei 同样长度的向量,那么此时我们称门为bit-wise gate,如果输出的gi 是一个值,那么此时称门为vector-wise gate。分别如下:

另一种就是是否所有的域都用同一个参数矩阵W,如果每个域的参数矩阵都不相同,那么被称之为field private,如果所有域的参数矩阵相同,则称之为field sharing。
后续会用实验对比这四种做法的效果。(插一句,有没有觉得和之前一篇新浪的FiBiNet的行文很像,特别是这个参数矩阵相同和不同的这个实验点完全一样,我又去翻了下,果然作者都有张俊林老师,哈哈~)
2.2 Hidden Gate
同理,Hidden Gate就是在多层感知机环节增加了门控机制,用于选择更加重要的特征交互传递到更深层的网络。如果模型中带有Hidden Gate,其网络结构如下图所示:
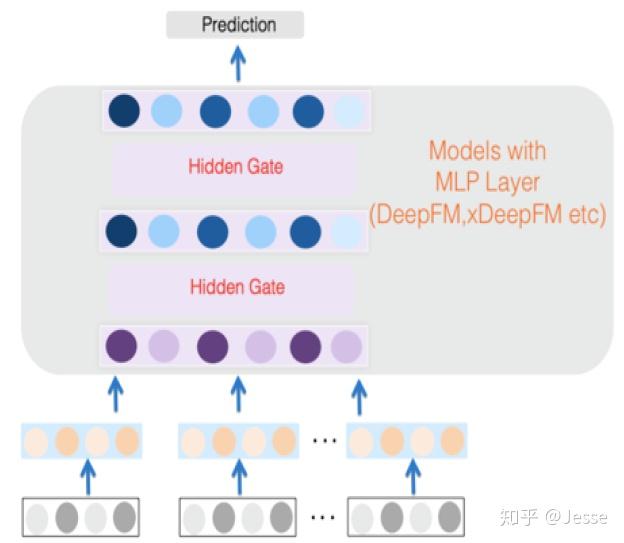
假设 a⁽ˡ⁾ 是第l层隐藏层的输出:
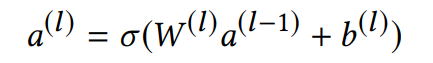
接下来将 a⁽ˡ⁾ 输入到hidden gate中,计算方式如下:
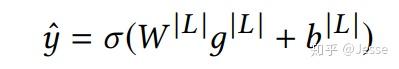
损失函数采取交叉熵损失函数。其余部分均与普通DNN相同。
3、 实验
首先来看下在网络中单独加入Feature Embedding Gate的效果:

可以看到加入Feature Embedding Gate后,在多个模型以及多个数据集中都取得了更好的AUC。
接下来对比前文提到的四种不同做法,field private和field sharing,以及bit-wise gate和vector-wise gate哪种效果更好。实验结果如下:
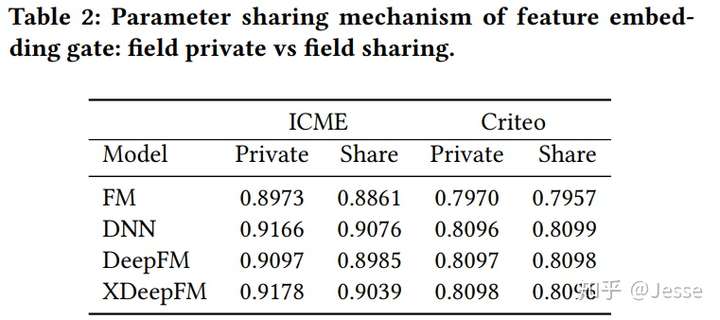
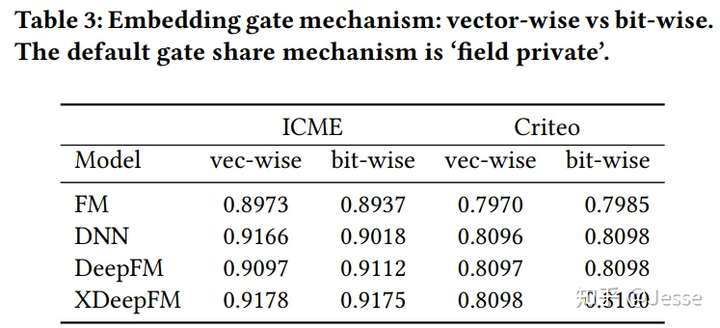
可以看到,field private的结果是明显好于field sharing的,但在不同的数据集中,bit-wise gate和vector-wise gate表现有所差异。
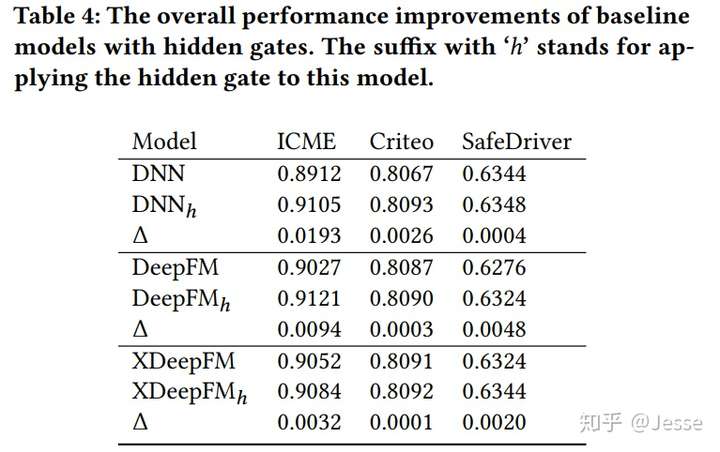
然后是在MLP中加入Hidden Gate的效果,加入Hidden Gate后性能也有一定的提升:
作者最后对两种gate进行结合,效果如下:
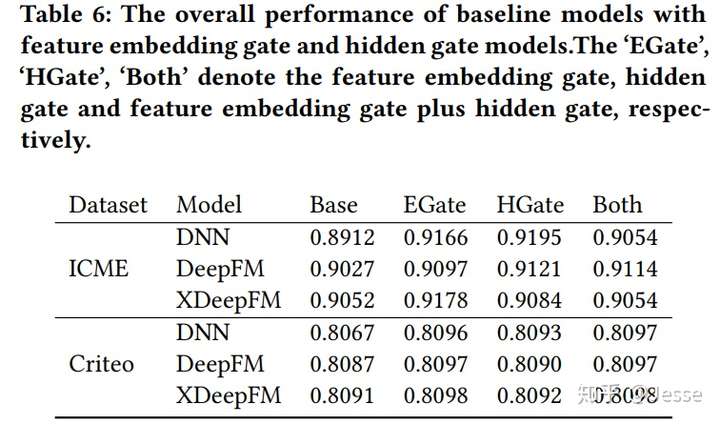
实验发现同时加入两种gate的效果其实还不如单独一种gate好,具体的原因还需要进一步验证,本文暂未提及。
本文介绍就到此结束,总的来说感觉像是使用了门控机制的两层attention来结合点击率预测,不是很有新意。在本文中门控机制介绍的较为简略,感兴趣的同学可以看一波LSTM之类的介绍。另外,最近不忙开始逐步恢复更新今年较新的论文啦~