本人才疏学浅,不足之处欢迎大家指出和交流。
继续更新,今天要分享的是阿里系第三篇CTR预估文章:Deep Session Interest Network(IJCAI19)。要点:作者们发现用户的行为在每一个会话和异构交叉会话中是高度同质(同构或异构)的,因此提出了DSIN模型,利用用户多个历史会话来模拟CTR预测任务中的用户系列行为。下面一起来看下吧。
原文:《Deep Session Interest Network for Click-Through Rate Prediction》
一、引入
由论文中相关的介绍,虽然目前绝大多数的CTR预测模型都是从用户历史行为数据中去建模他们动态、不断变化兴趣特征,但是大多数都停留到behavior sequence序列的阶段便不再分析下去了。
而如何从用户历史行为数据中建模他们动态、不断变化的兴趣特征已经成为CTR预估的一个关键问题,如之前阿里的DIN/DIEN来建模用户的兴趣特征。但是大多数工作还是忽略了用户行为序列(sequences)内在的结构:用户的行为sequences其实是由多个会话(sessions)组成,其中多个sessions是通过用户的点击时间(同airbnb)来区分。
这里可以看到其实sessions和sequence性质上都是由多个behaviors组成。但是session是根据一定时间规则对sequence进行划分的结果。 (一个sequence由k个session组成 )
如下图,将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min,就进行切分。可以看到,第一个session中,用户查看的都是跟裤子相关的物品,第二个session中,查看的是戒指相关的物品,第三个则是上衣相关。从中可以观察到用户的行为在每一个session中行为是高度相近的(同构),在不同session间行为是差别较大的(异构)。
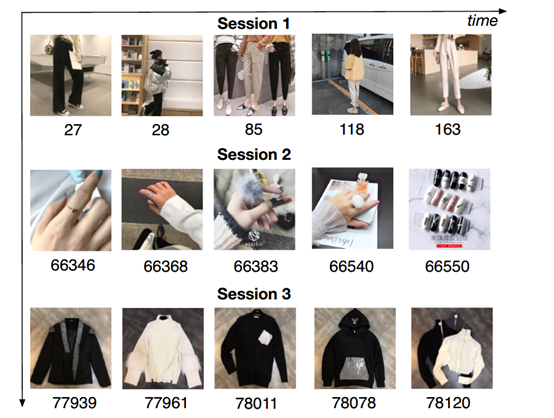
这说明用户在同一个session下对购买商品有一个明确的、单独的需求,但是一旦开启一个新的session,他的兴趣将会发生很大的变化。基于该观察,作者提出了一个CTR预估模型,被称作Deep Session Interest Network(DSIN)。该模型充分利用了用户的多个历史行为sessions。
模型要点:
· 首先,根据点击时间将用户的行为序列划分成多个sessions,并使用带有bias编码的自注意力模块来抽取用户每个session的兴趣特征。
· 在第二部分使用Bi-LSTM去捕捉用户在多个历史会话中兴趣的交互和演变。
· 最后使用local activation单元来整合目标item对于不同session兴趣的重要性。
二、模型
Base Model
Base Model是一个MLP网络,在base model中输入特征分为三部分:用户特征,待推荐物品特征,用户历史行为序列特征(UBS)。用户特征包括性别、城市、用户ID等等,待推荐物品特征包含商家ID、品牌ID等等,用户历史行为序列特征主要是用户最近点击的物品ID序列。当然一些item的side information也可以加到输入特征中。
这些特征分别通过Embedding层转换为对应的embedding向量,拼接后输入到多层全连接中,并使用logloss指导模型的训练。(也就是普通的DNN)
DSIN
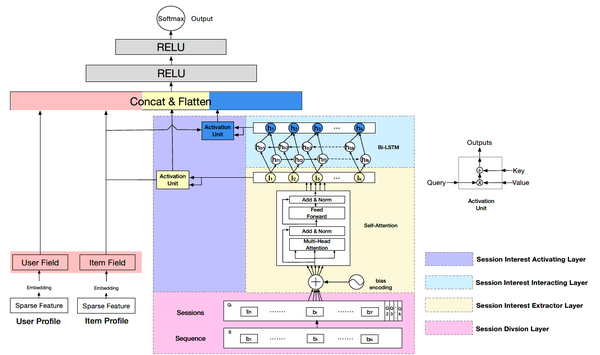
整体的结构如上图所示,模型在MLP之前DSIN包含左右两大部分,其中左边部分是用户特征和待推荐物品特征通过embedding层转换对应的向量表示然后进行拼接;右边部分主要是对用户行为序列进行建模,是本文重点,从下到上分为四层:
1、session division layer
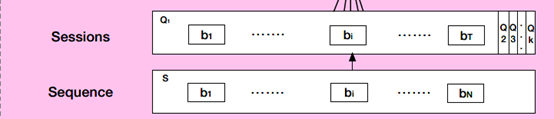
如下图将用户的历史点击行为序列S进行切分:首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,如果前后的时间间隔大于30min,就进行切分。切分后,我们可以将用户的行为序列S转换成会话序列Q。第k个会话Qk=[b1,b2,…,bi,…,bT] , 其中,T是会话的长度, bᵢ 是会话中第i个行为。(分解的方式可以视实际情况,论文中作者是按间隔时间30分钟来分解的。)
2、session interest extractor layer
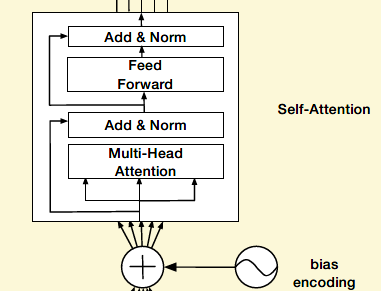
前文说到在同一个session中的行为是高度相近的,而用户在当前session下的随意的一些行为会使得session的兴趣表示变得不准确。所以这里对每个会话都使用Transformer中的多头自注意力机制(multi-head self-attention)来抽取用户session的兴趣特征,捕获行为之间内部关系,减少不大相关行为的影响。有关多头自注意力机制,请参考:细讲 | Attention Is All You Need
具体过程为:为用户行为序列中的每个session添加一个Positional Encoding,该模块被称为Bias Encoding ,BE中的每个元素都分为三块:
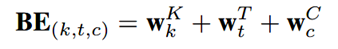
其中BE是K×T×d维的。BE(k,t,c)是第k个session中,第t个物品的embedding向量的第c个位置的偏置项。也就是说,对每个session中的每个物品对应的embedding的每个位置,都加入了偏置项。加入偏置项后更新Q,Q是用户行为session的表示:
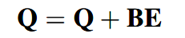
在推荐系统中,用户的点击行为会受各种因素影响,比如颜色、款式和价格(这些就作为多头注意力中的head)。Mulit-head self attention 模块可以在不同的表示子空间层面上建模这种关系。这里让 Qₖ 表示为:
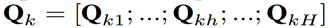
其中 Qₖₕ 是T×dₕ的,它是 Qₖ 的第h个head,H是head的数量。其中第h个head的输出为:
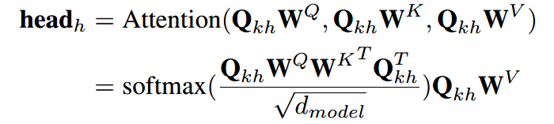
然后将不同的头连接起来喂给前馈网络:
经过Mulit-head self attention 处理之后,每个Session得到的结果仍然是T * d大小的,随后,经过一个avg pooling操作,将每个session兴趣转换成一个d维向量。
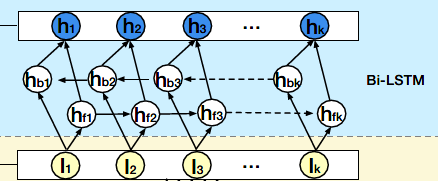
3、session interest interacting layer
在提取出每个session的interest后,很自然就会想要去捕获不同session之间的顺序关系,这里DSIN使用了Bi-LSTM来做这件事。每个时刻的hidden state计算如下:
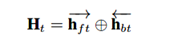
相加的两项分别是前向传播和反向传播对应的t时刻的hidden state。这里得到的隐藏层状态Ht,可认为是混合了上下文信息的会话兴趣。
4、session interest activating layer
这一层建模不同session和target item的关联度。也就是说用户的会话兴趣与目标物品越相近,越应该赋予更大的权重。使用注意力机制来刻画这种相关性:
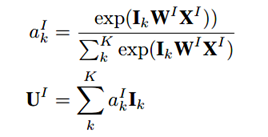
同样,对于混合了上下文信息的会话兴趣,也进行同样的处理:
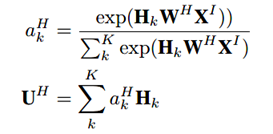
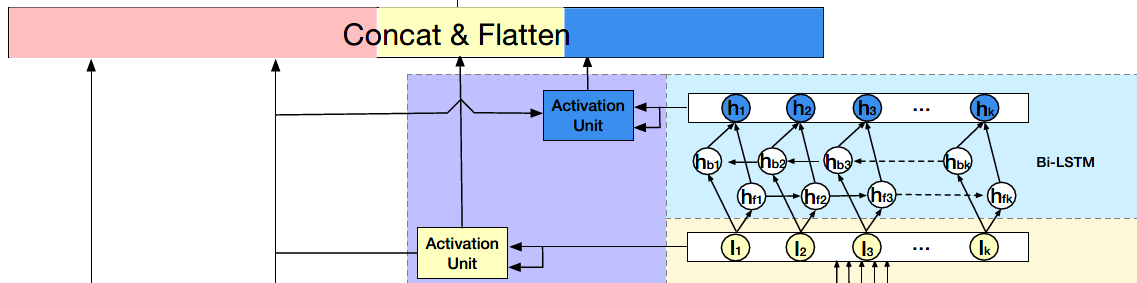
最后将User profile向量、Item profile向量、会话兴趣加权向量UI、带上下文信息的会话兴趣加权向量UH进行横向拼接,输入到全连接层中,得到最终的输出。
三、实验
作者在广告和推荐系统上都有评估。使用了两个数据集进行了实验,分别是阿里妈妈的广告数据集和阿里巴巴的电商推荐数据集。对比模型有YoutubeNet、Wide & Deep、DIN 、DIN-RNN、DIEN,评价指标为AUC。结果:

其他相关实验细节参阅原论文。
实现DSIN的一个Demo,感兴趣的童鞋可以看下我的[github]。