本人才疏学浅,不足之处欢迎大家指出和交流。
本文介绍的是第四范式提出的全新的深度神经网络表数据分类模型——深度稀疏网络(Deep Sparse Network,又名NON)。要点:在推荐系统中,如何根据用户的历史行为和item的特征信息,判断用户对商品是否感兴趣成了重要的研究问题之一。而目前的基于模型的方法(如浅层模型如LR,深度模型DNN等)存在一些问题:
- 首先,这些方法会直接融合不同特征域的向量表示,而未显式地考虑域内信息;
- 其次,大多数现有方法使用预定义的特征域交互操作组合(如 DNN、FM),而未考虑输入数据。事实上,预定义的操作组合并不适用于所有的数据,而是应该根据数据选择不同的操作,以获得更好的分类效果;
- 最后,现有方法忽略了特征域交互操作(如 DNN 和 FM)的输出之间的非线性,即最后的输出层均采用的是线性加权的方式,忽略了不同模块输出之间的非线性关系。
为了解决上述问题,本文提出了NON模型(Network On Network),下面一起来看下细节。
原文:《Network On Network for Tabular Data Classification in Real-world Applications》
一、引入
本节具体介绍上述所提的三个问题。
大多数推荐系统中所使用的数据都是表格型数据,如下图所示,每一列可以称为一个field:

目前可以将推荐系统分为以下四类,基于内容的推荐算法、基于协同过滤的推荐算法、混合推荐算法及基于模型的推荐算法。这里暂时略过其余三个,重点介绍下基于模型的推荐算法,它可以分为两类:
1. 浅层的基于模型的方法
首先,是一些基于浅层模型的推荐方法,例如LR、FM、FFM等。逻辑回归算法 ( Logistic Regression,LR ) 是推荐系统的常用方法之一。将用户的浏览记录和项目的信息、离散特征,通过one-hot编码;将数值类特征归一化,或者通过分桶技术,进行离散化;然后通过LR模型进行训练。LR模型很稳定, 但是缺乏学习高阶特征的能力,尤其是特征间的交互。而FM模型和FFM模型则将高度的离散特征通过embedding,转化为低维的稠密向量。然后用稠密向量的内积表示特征之间的交互特征。
2. 基于深度学习的方法
基于深度学习的推荐方法,如Wide & Deep,DeepFM、xDeepFM和AutoInt,这些模型均由DNN和其他的交互操作如Linear、FM、Self-attention、CIN等一项或几项组成(如下图),在最后的输出层,将这几部分输出进行线性加权,最后经过sigmoid后得到点击率预估值:
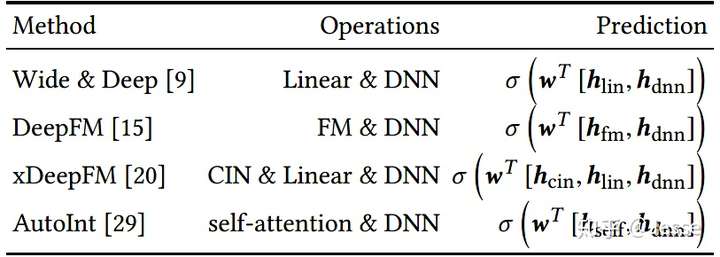
但上述的模型存在以下三方面的问题:
- 现有方法直接融合不同特征域的向量表示,而未显式地考虑域内信息。我们将”每个特征域内的不同特征值,均属于同一个特征域”记为域内信息。对于每个特征域中的特征,它们的内在属性是都属于同一个特征域。以在线广告场景为例,假设特征域 “advertiser_id” 和 “user_id” 分别表示广告商和用户的ID,则特征域 “advertiser_id” ( “user_id” ) 中的不同的广告商ID ( 用户ID ) 都属于广告商 ( 用户 ) 这个特征域。此外,特征域有自己的含义,如 “advertiser_id” 和 “user_id” 分别代表广告主和用户,而不管域内特征的具体取值。
- 不同的模型结构是确定的,在不同数据上的泛化性能不能保证。事实上,预定义的操作组合并不适用于所有的数据,而是应该根据数据选择不同的操作,以获得更好的分类效果。
- 最后的输出层都是将不同的结果通过线性求和关联起来,没有考虑非线性的关系。
下面我们来具体看下本文提出的模型。
二、NON模型
整个NON的模型结构如下图所示:
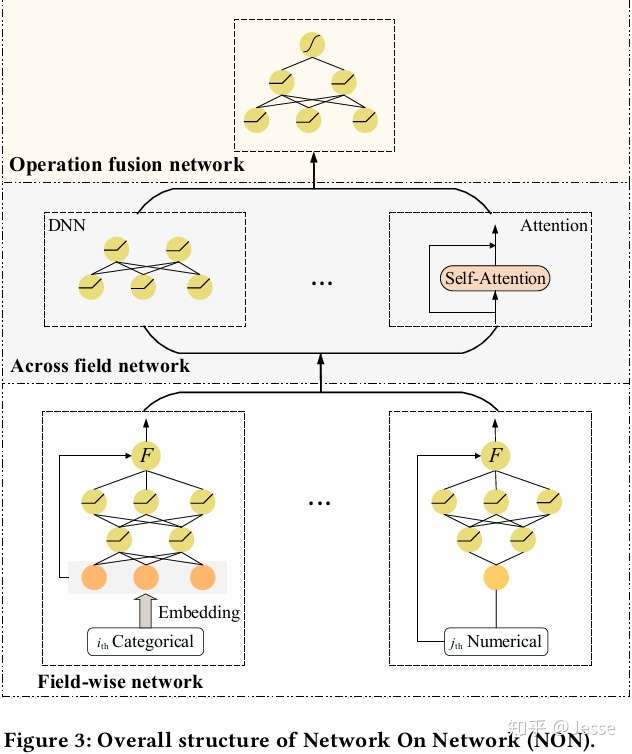
如图NON模型由三部分组成:底层为域内网络 ( Field-wise Network ) ,中层为域间网络 ( Across Field Network ),顶层为融合网络 ( Operation Fusion Network )。域内网络为每个特征域使用一个DNN来捕获域内信息;域间网络包含了大部分已有的Operation,采用多种域间交互操作来刻画特征域间潜在的相互作用;最后融合网络利用DNN的非线性,对所选特征域交互操作的输出进行深度融合,得到最终的预测结果。接下来对这三部分进行介绍。
2.1 Field-wise network
在Field-wise network中,每一个特征Field都和一个NN网络相连,其中类别特征先进行Embedding操作,而数值型特征直接通过NN网络。域对应的DNN网络用来提取域内信息:
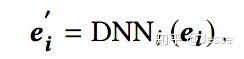
在网络的最后部分,会对原始的embedding和经过NN网络处理的embedding进行耦合:
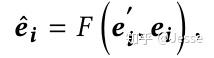
常见的F操作包括concatenation、element-wise product以及其他更加复杂的操作。对于Field-wise network的详细分析将在实验中介绍。
2.2 Across field network
经过Field-wise network,每个域输出对应的embedding,接下来就是我们比较熟悉的方式了。Across field network包含了多个常见的特征域交互操作,包括:LR、DNN、FM、Bi-Interaction和多头自注意网络等。其中Bi-Interaction是FM的泛化形式(也就是NFM中所使用的),计算公式如下:
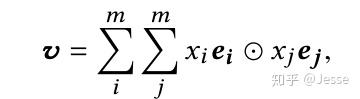
NON在设计上,兼容目前大部分学术上提出的Operation。在实际应用中,NON将Operation作为超参数,在训练过程中根据数据进行选择。现有方法中,域间交互操作的方式是用户事先指定的。而在深度稀疏网络中,可以通过数据,自适应地选择最合适的操作组合,即在深度稀疏网络中,操作组合的选择是数据驱动的。
2.3 Operation fusion network
在最后的融合网络Operation fusion network,首先将Across field network各模块的输出进行拼接,再经过DNN网络得到最终的输出:
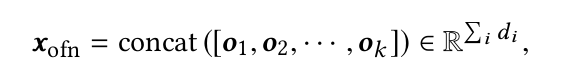
需要注意一点,NON网络设计的特别深,所以在训练过程中,很容易出现梯度消散的现象,导致模型效果变差。受到GoogLeNet的启发,本文在模型训练过程中引入了辅助损失。在DNN的每一层都加入了一条路径,连接到最终的损失上,缓解了梯度消散问题。经测试,该方案不仅能够增加模型最终预测效果,也使得模型能在更短的时间内,取得更好的效果。如下图所示。
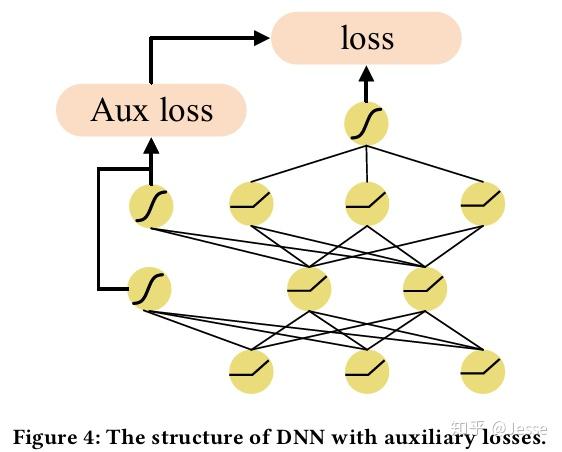
具体来说,对每一层网络的输出,都通过一层LR来预测对应的点击率,并与真实值计算logloss,这样每一层网络都能够有不错的区分性:
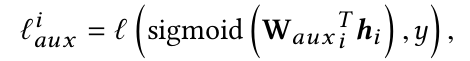
最终的loss形式为:
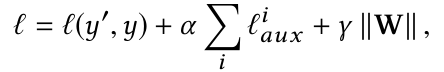
现在可以看到,模型的三个部分分别解决之前提出的三个问题:
- 使用Field-wise network来提取域内信息;
- 使用Across field network融合不同的交互模块,交互模块可任意组合;
- 通过Operation fusion network,以非线性的方式融合各模块的输出,并通过辅助loss来加速网络学习,同时避免梯度消失现象。
三、实验
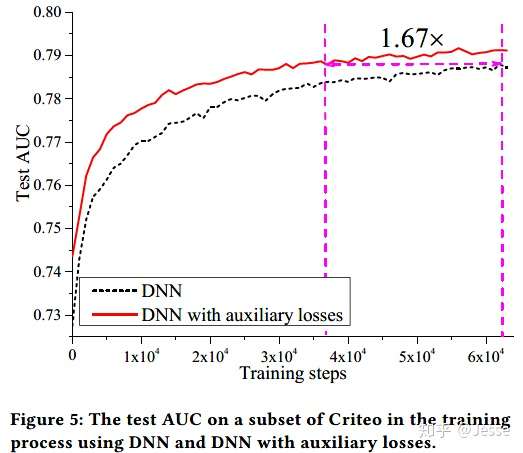
DNN with auxiliary losses
最后我们来看下实验分析。
首先验证下辅助loss的效果。下图是在Criteo数据集上的实验结果,图中的横坐标是训练的轮次,纵坐标是AUC。从图上可以看出,通过添加辅助损失,训练效率明显提升。在同等AC的情况下,得到了1.67倍的加速。之后的所有训练都是通过添加辅助函数的方式进行训练的。
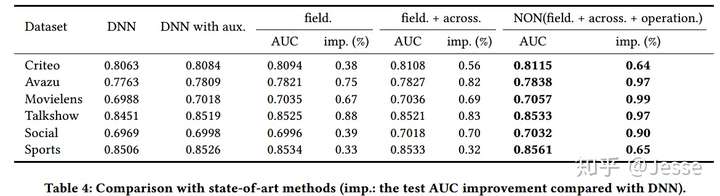
Ablation study of NON
其次在消融实验中,展示NON每一个模块的作用和整体的效果。从下表来看,当包含所有的三个组件时,NON在所有的数据集上都达到了最好的结果:
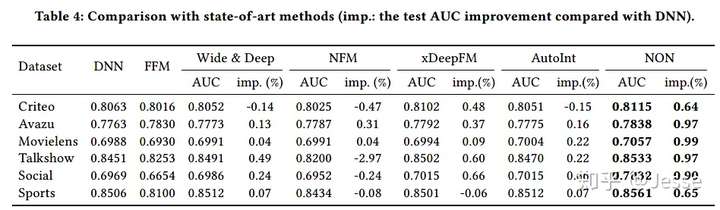
Comparison with SOTAs
再与其他baseline模型相比,NON能否取得更好的效果。从下表看,在不同的数据集上,NON都取得了比baseline模型更好的结果;再看一些细节,在Talkshow数据集上,NFM模型的效果退步,说明网络不一定越复杂越好,需要进行仔细设计,才能获得较好的结果。结果证明了NON模型设计范式的有效性。
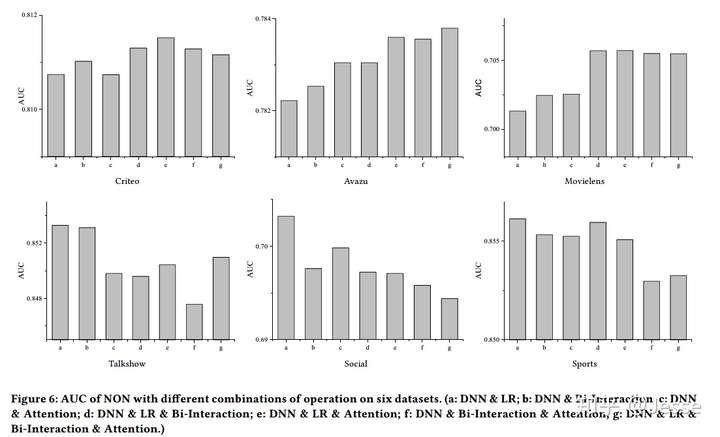
Study of operations
然后再对不同操作的组合进行实验。对于不同的数据集来说,在Across field network使用的模块是否都是相同的?如果不同,不同的数据集使用的最优模块组合是什么?可以看出没有一个操作组合能够在所有数据集上都取得最优效果,也没有一个Operation组合能够在所有的数据集上都取得最好的效果,这表明了根据数据选择操作组合的必要性。不过可以总结出的一条经验是:对于小数据集来说,选择更少的模块能够取得更好的效果,对于大数据来说,需要更多更复杂的操作来取得更好的效果。
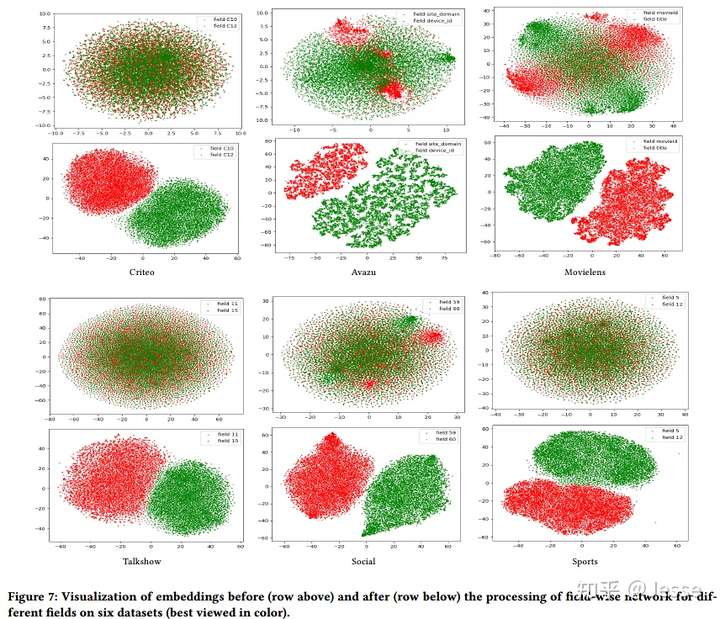
Study of field-wise network
最后看下field-wise network能否有效提取域内信息。下图第一行表示通过Field-wise network之前,第二行是通过Field-wise network之后。不同的颜色表示不同Field之间的Embedding。通过对Field-wise network处理前后特征值对应的向量进行可视化和比较,可以看出经过Field-wise network后,每个Field内的特征在向量空间中更加接近,不同Field间的特征也更容易区分。
四、总结
本文是最近码字最多的一篇文章,从这个量也能凸显出本文提出模型的结构复杂程度。当然这并不是说NON模型的理论构造有多么复杂,而是说它在组合其他模型的操作结构的方式上略显复杂(一定程度上去做排列组合来得到最优解),这会带来一个明显的问题即训练的时间问题,显然这个模型的参数量比任何一个现有模型都要大,因为在Embedding和Prediction层都加了Network,而且选择了很多个Operation;其次,将operation作为超参数在工业界的代价太大,需要训练的时间更长。作者也在文章中分析了时间复杂度的问题,并且给出了建议,在保证效果的前提下选择轻量级的Operation组合。
但本文同样也是较好的一篇文章。论文中提出的网络结构,辅助loss这几个思路都不错;且NON可以看成是模块化的系统,尤其是Cross field network层,从wide&deep模型开始,越来越多的模型使用类似的并联结构,但NON模型提出这样的观点:把其他的模型结构都放进来作为超参数,调参以得到最好的结果。以后若是产生了新的模型,也可以放进去作为模块进行训练组合。所以只要选得好,模型的结果应该是会比SOTAs的模型好的。不过另一方面这也会为人诟病: NON模型是不是可以看成模型融合呢?个人觉得,在一定程度上是可以的。但即使是融合所带来的提升也能为我们提供一个新的思路,何尝不可呢。
本文介绍就到此结束,感兴趣同学可以阅读下原文。